
Jae Hossell

We recently agreed a custom Service Level Agreement(SLA) with one of our enterprise customers and one thing the process highlighted was that we don’t talk about Approov’s backend enough. In this post, I hope to remedy that slip by providing a brief overview while dwelling on the characteristics indicative of a quality cloud service.
Getting consensus on the attributes of a good cloud architecture, or even accepted terminology, is beyond scope; there are many views, as well as advice from the biggest providers: aws, azure, and google cloud. However, for a Software as a Service(SaaS) solution such as Approov, I think most people would include the following qualities at the top of the list, in one order or another:
Not to give the game away too quickly, the Approov service has been designed to hit each of these desirable qualities and then, where possible, go further. First an overview diagram:
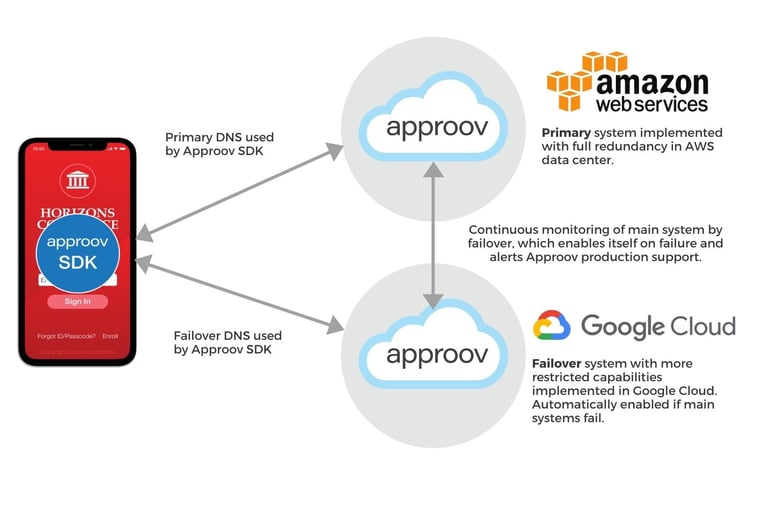
Here we see the top-level service components and how they communicate with an Approov SDK embedded in an app. I will summarise each of the components in turn in the following sections.
The primary Approov service (Primary) runs in AWS and, in normal operation, this is the only server-side component that sees any communication with the app. The Primary provides ubiquitous access by running across multiple regions where necessary. It has resiliency and redundancy by having multiple instances per region, spread across the AWS Availability Zones(AZs). Each instance is completely autonomous and does not need to communicate with the other running instances, although there is shared access to AWS services; Dynamo and S3. It provides elasticity by auto-scaling instances to meet demand, balancing new instances across the region’s AZs. Lastly, our ops team manages the security of the service; patching platform and software dependencies as necessary and monitoring access to our service and the resources that it uses. We have alarms set for many interesting behaviors and a 24/7 on-call rota for handling issues.
By following the best practices of cloud-native architecture, we ensure that our uptime SLAs are aligned with Amazon's - allowing us to instead focus on more specific SLOs for our customers' use cases (such as latency or incident response time).
Wikipedia defines failover as the automatic process of switching to a redundant or standby system upon the failure of the previously active one. In the Approov architecture, the redundancy inherent in the Primary already satisfies this definition and our main aim when developing the Approov failover (Failover) was not to provide a duplicate service. Instead of focusing on individual components in the Primary we were really looking at the Primary as a whole and asking the questions: What if that system goes down? What could be the cause?
Planning for catastrophic failure of AWS is quite sobering but it resulted in an interesting service. The idea is to minimise the number of components and services shared between the two environments. The Failover runs with a different cloud provider, is written in a different programming language, connects to a different DB, runs on a different Linux distribution, and even uses a different Top-Level-Domain in the service URL (remember this in Sep 2017). Both Primary and Failover still use a Linux kernel and the basic Linux libraries, but, on the whole, we think we’ve done a good job.
The behavior of the Failover is also scaled back. Instead of a full duplicate service, it provides a lighter weight attestation service in exchange for confidence that your apps will keep running. By default, the Failover is in a mode that polls the Primary's health endpoint; tokens are only served if the Primary is down. The default can be manually overridden to turn token serving on or off. Ultimately, we believe this approach helps give your apps maximum uptime even in the event of an major outage.
Although simple, a subtle aspect of the setup is that our SDK must automatically switch from Primary to Failover and back again without intervention from either of our backend services, or the running app. Our solution is as follows:
I could go into more detail on several aspects mentioned here but I think this is a good place to close for now. I have introduced Approov’s high quality server-side components and shown how they work together to provide a highly resilient cloud service. As always, if you have questions about any points raised here, or any other aspect of Approov, then please contact me. I will certainly follow up with a blog about our rigorous release process in the near future.
This series of posts focuses on aspects of Approov that are sometimes misunderstood. If you have any issues you want qualified then why not ask me a question from the contact us page. Otherwise, here are some links that you may find interesting:
